A01 - 爬蟲基本介紹
📄目錄
A01 - 爬蟲基本介紹📄目錄1 爬蟲概念1.1 請求過程1.2 爬蟲的概念1.3 爬蟲的作用2 爬蟲分類3 爬蟲基本流程介紹3.1 robots協議4 請求頭4.1 網絡通信4.2 http協議和https協議4.2.1 http請求/響應的步驟4.3 請求頭4.3.1 請求方式4.3.2 常見的響應狀態碼4.3.3 User-Agent4.3.4 Cookie4.3.5 Referer4.3.6 總結導航連結:
1 爬蟲概念
統一資源定位符(url)
例子:
1.1 請求過程
客戶端,指web瀏覽器向服務器發送請求
請求分為四部分:
請求網址(
request url)請求方法(
request methods)請求頭(
request header)(爬取大量數據時,容易被服務器識別是爬蟲程序;請求頭可以偽裝為一個正常用戶)請求體(
request body)
1.2 爬蟲的概念
模擬瀏覽器
發送請求
獲取響應
只能獲取客戶端所展示出來的數據
特點:知識碎片化
在寫爬蟲的時候會面對各種各樣的網站,每個網站都是有區別的
模擬客戶端,操作者是正常的用戶
作為一個爬蟲身份,服務器是不歡迎的,盡可能地去模擬正常用戶發送請求
爬蟲:模擬客戶端訪問,抓取數據
反爬:保護重要數據,阻止惡意網絡攻擊
反反爬:針對反爬做的措施
1.3 爬蟲的作用
數據採集
軟件測試
搶票
網絡安全
web漏洞掃描
2 爬蟲分類
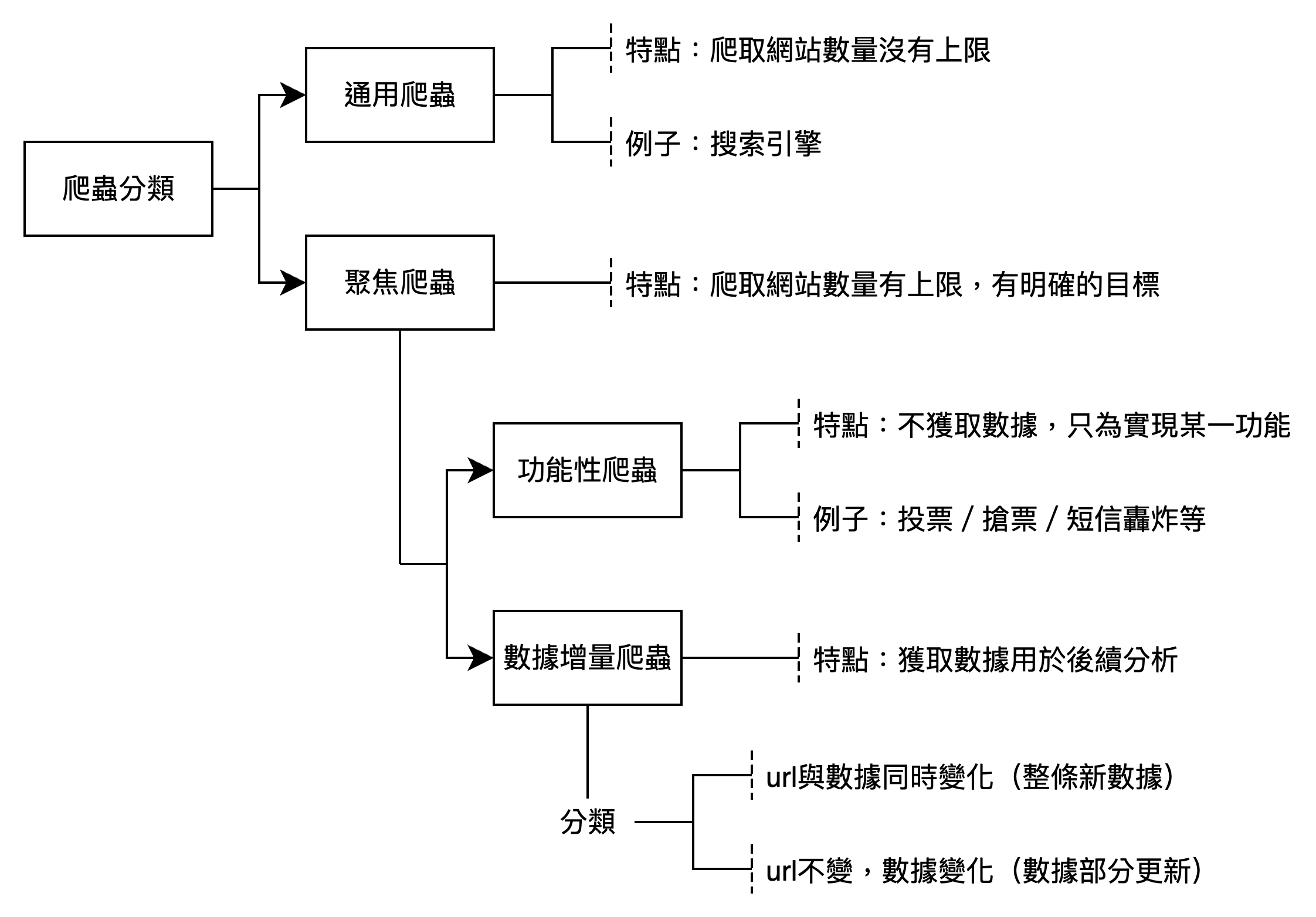
根據爬取網站的數量,可以分為:
通用爬蟲(如搜索引擎)
聚焦爬蟲(如搶票)
根據獲取數據的目的,可以分為:
功能性爬蟲(如投票、點讚)
數據增量爬蟲(如爬取招聘信息)
本課程主要學習聚焦爬蟲
3 爬蟲基本流程介紹
確認目標:url(網址資源定位符)
發送請求:發送網絡請求,獲取特定的服務端給予的響應
提取數據:從響應中提取特定的數據(jsonpath/xpath/re/正則)
保存數據:本地(html、json、txt)、數據庫

獲取到的響應中,有可能會提取到還需要繼續發送請求的url,可以拿着解析到的url繼續發送請求
3.1 robots協議
robots協議並不是一個規範,而是一個約定俗成的習慣。
通常是一個robots.txt,放置於網站根目錄,告訴搜索引擎等訪問者,哪些內容可被漫遊器(或爬蟲器)獲取,哪些不能。
4 請求頭
4.1 網絡通信
網站實際上由很多部分組成:
html:文本
css:樣式,控制文字大小、顏色
js:行為,包括鼠標點擊
jpg:圖片
⋯⋯
訪問過程:
電腦(瀏覽器):url(如
www.google.com)DNS服務器:ip地址標注服務器(如
1.1.1.1)DNS服務器返回ip地址給瀏覽器
瀏覽器拿到ip地址去訪問服務器,返回響應
服務器返回給我們的響應數據,一般有html、css、js、jpg⋯⋯
網絡通信的實際原理:
一個請求只能對應一個數據包(文件)
之後抓包可能會有很多個數據包,共同組成了整個頁面
4.2 http協議和https協議
規定了服務器和客戶端互相通信的規則
http協議:超文本傳輸協議,默認端口是80
超文本:不限於文本,還包括圖片、音訊、影片
傳輸協議:指使用共同約定的固定格式來傳遞轉換成字符串的超文本內容
https協議:HTTP + SSL(Secure Sockets Layer,即安全套接字層),默應端口是443
帶有安全套接字層的超文本傳輸協議
SSL:對傳輸的內容進行加密
比http更安全,但是性能更低
4.2.1 http請求/響應的步驟
客戶端連接到web服務
發送http請求
服務器接受請求,返回響應
釋放tcp連接
客戶端解析html內容
4.3 請求頭
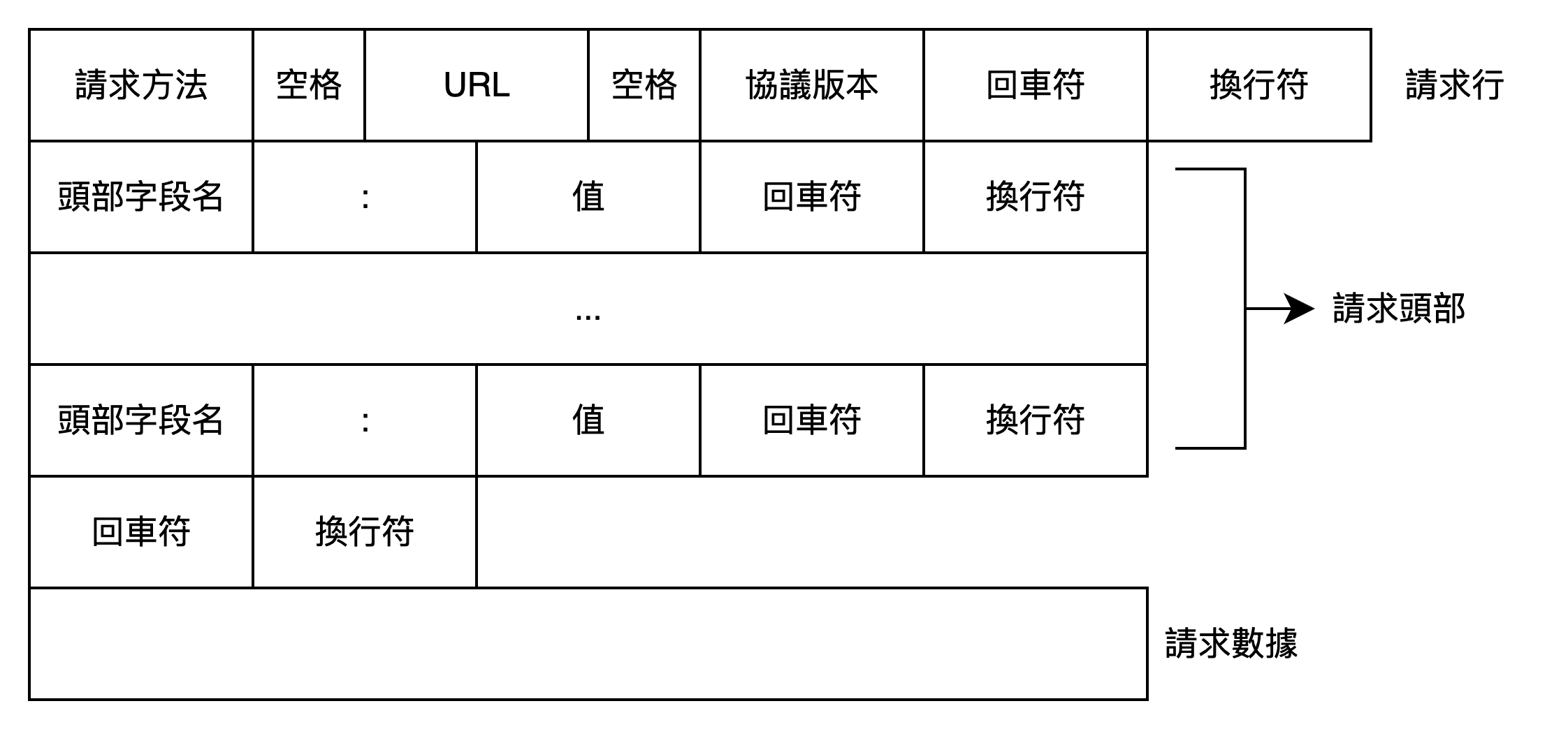
4.3.1 請求方式
get和post
get:向服務器要資源post:向服務器提交資源
4.3.2 常見的響應狀態碼
200:成功
302:跳轉,新的url在響應的Location頭中給出
303:瀏覽器對於POST的響應重定向至新的url
307:瀏覽器對於GET的響應重新向至新的url
403:資源不可用;服務器理解客戶的請求,但拒絕處理它(沒有權限)
404:找不到該頁面
500:服務器內部錯誤
503:服務器由於維護或者負載過重未能應答,在響應中可能會攜帶Retry-After響應頭;有可能是因為爬蟲頻繁訪問url,使服務器忽視爬蟲的請求,最終返回503響應狀態碼
如何查看響應狀態碼:
在Chrome上打開任意網頁,右鍵後點選「檢查」,選擇「Network」,在「Header」中的「Status Code」就是響應狀態碼
4.3.3 User-Agent
模擬正常用戶
在Chrome上打開任意網頁,右鍵後點選「檢查」,選擇「Network」,在「Header」中滑至最底部即可找到
4.3.4 Cookie
登錄保持
4.3.5 Referer
當前這一次請求是由哪個請求過來的
4.3.6 總結
抓包得到的響應內容才是判斷依據,elements中的源碼是渲染之後的源碼,不能作為判斷標準
導航連結:
| 目的地 | 超連結 |
|---|---|
| 首頁 | 返回主頁 |
| Python學習 | Python學習 |
| 上一篇 | 本篇為第一篇 |
| 下一篇 | A02 - Requests庫基本使用 |